
测信道攻击——利用一个bit恢复AES key
前面对AES原理做了解释,而本实验的AES是一个半AES,因为没有那么复杂,非常简单,方便初学者理解。这次实验不用硬件设备。实验的目的就是通过一个bit位的泄漏,即使不知道key,但知道加密算法也可以恢复完整的AES key,这个方法非常妙!
简单来说,本实验的阉割版AES长这样:
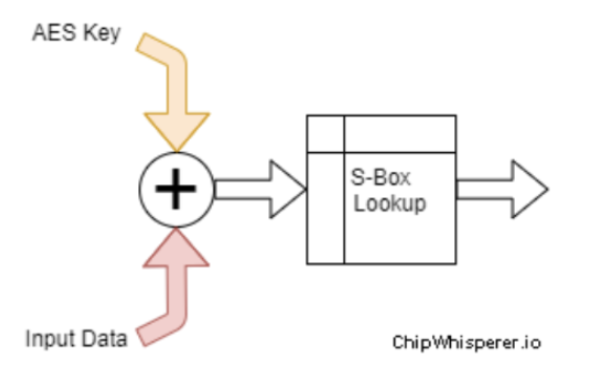
S-box
1 | sbox = [ |
定义aes_internal用于返回加密后的秘文,加密后的秘文就是AES key和输入异或的值在s-box中对应的数值
1 | def aes_internal(inputdata, key): |
这里可以验证一下:
1 | assert(aes_internal(0xAB, 0xEF) == 0x1B) |
接下来就是设置一个要攻击的目标,定义一个新的函数aes_secret,不透露key,内置一个固定的key。
1 | def aes_secret(inputdata): |
这段代码就是教我们怎么用python生成随机数,并且通过加密函数得到output(这里somefunc是一个例子,不是前面说的要用的加密函数)
1 | ##Some Python hints/useful functions: |
生成1000个0~255的随机整数:
input_data = [random.randint(0,255) for _ in range(0, 1000)]
接下来是生成泄漏数据,取input的最低bit位,& 0x01就是取最低比特位的作用,这样计算出来就能把最低比特位给泄漏
1 | leaked_data = [(aes_secret(a) & 0x01) for a in input_data] |
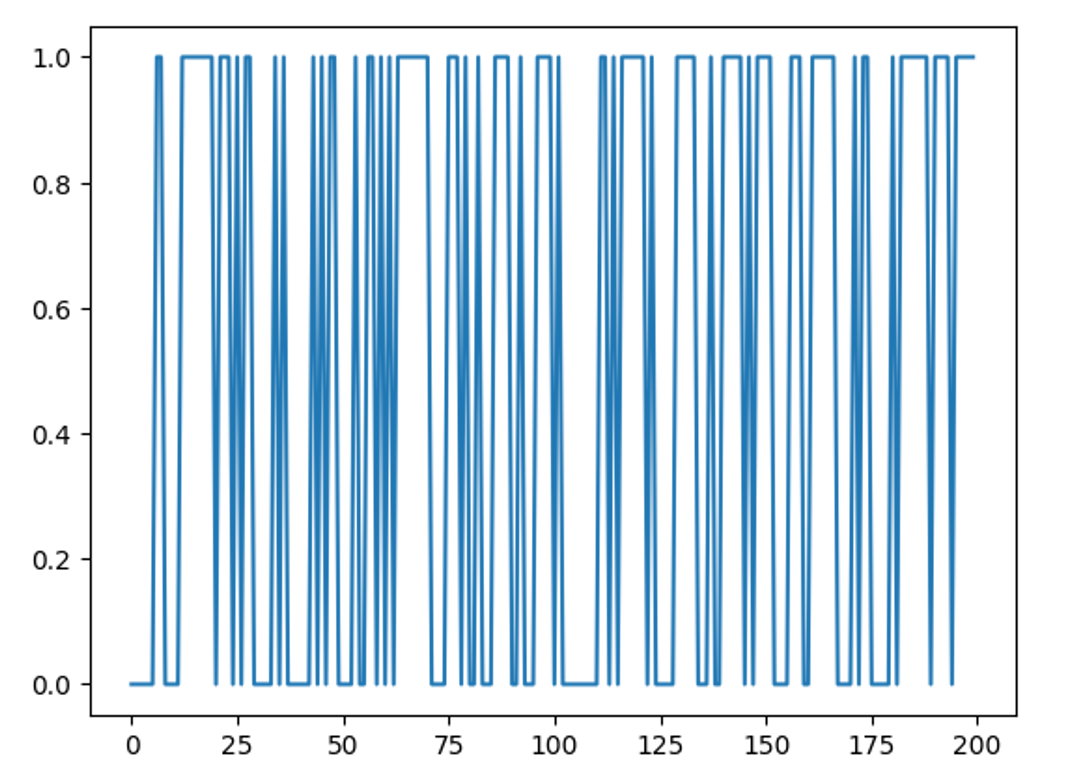
输出的就是泄漏的1000个数据每个数据最低比特位数
1 | [0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1] |
通过画图可以直观查看泄漏数据leaked_data的内容
1 | import matplotlib.pylab as plt |
这里介绍一下要获得两个list相同元素的数量可以先转化为numpy array,然后两个array进行比较,最后sum出True(1)的数量
1 | def num_same(a, b): |
可以检测下是否正确实现代码块
1 | #Simple test vectors - if you get the check-mark printed all OK. |
那么利用上面比特位的泄漏方式以及判断两个array是否相同的方法, 我们就可以枚举所有key的可能,key的一个字节就是0x00~0xff,将这些所有可能去加密相同的input_data得到key_guess,再将结果和泄漏数据的这个list进行比较,看是否相同!发现EF是1000,代表之前随机生成的1000个数据,在AES加密后生成的密文的最低比特位(1000个数据1000个最低比特位)与我们从枚举一个字节的所有可能值(0x00~0xFF)中的0xEF对同样的明文加密后,产生的密文是一样的!(因为最低比特位1000个都一样,而且唯一也就它是正好1000),所以0xEF就是密钥key的一个固定字节!那么按照这个思路,继续猜测密文的其他字节也同样可行,这招真的是妙啊!
1 | Guess 00: 487 bits same |
上面已经够妙了,然鹅我们还可以在算法上更优化下,不那么傻傻地一个个找了,怎么做呢?这里先介绍下numpy的argsort用法,np.argsort函数用来输出从小到大数值对应的index,这里输出就是“0 3 4 1 2“,要从大到小就是[::-1]或者np.argsort(-np.array(list()))
1 | import numpy as np |
到这里,应该能知道为啥要介绍这个函数了吧,我们可以直接把结果从大到小排序,只考虑前五个guess key的结果
1 | import numpy as np |
结果如下,还是很明显的,EF最多,而且一字不纳
1 | Key Guess EF = 1000 matches |
接下来就是如何猜测key中的下一个字节呢?,其实只要稍微修改下前面的leaked_data函数代码就ok,比如前面一个字节,那么就是第‘3’位的数据
1 | leaked_data = [(aes_secret(a)>>3 & 0x01) for a in input_data] |
继续完善leaked_data函数,让它根据随机数来决定返回正确加密结果还是0,来模拟噪声
1 | import random |
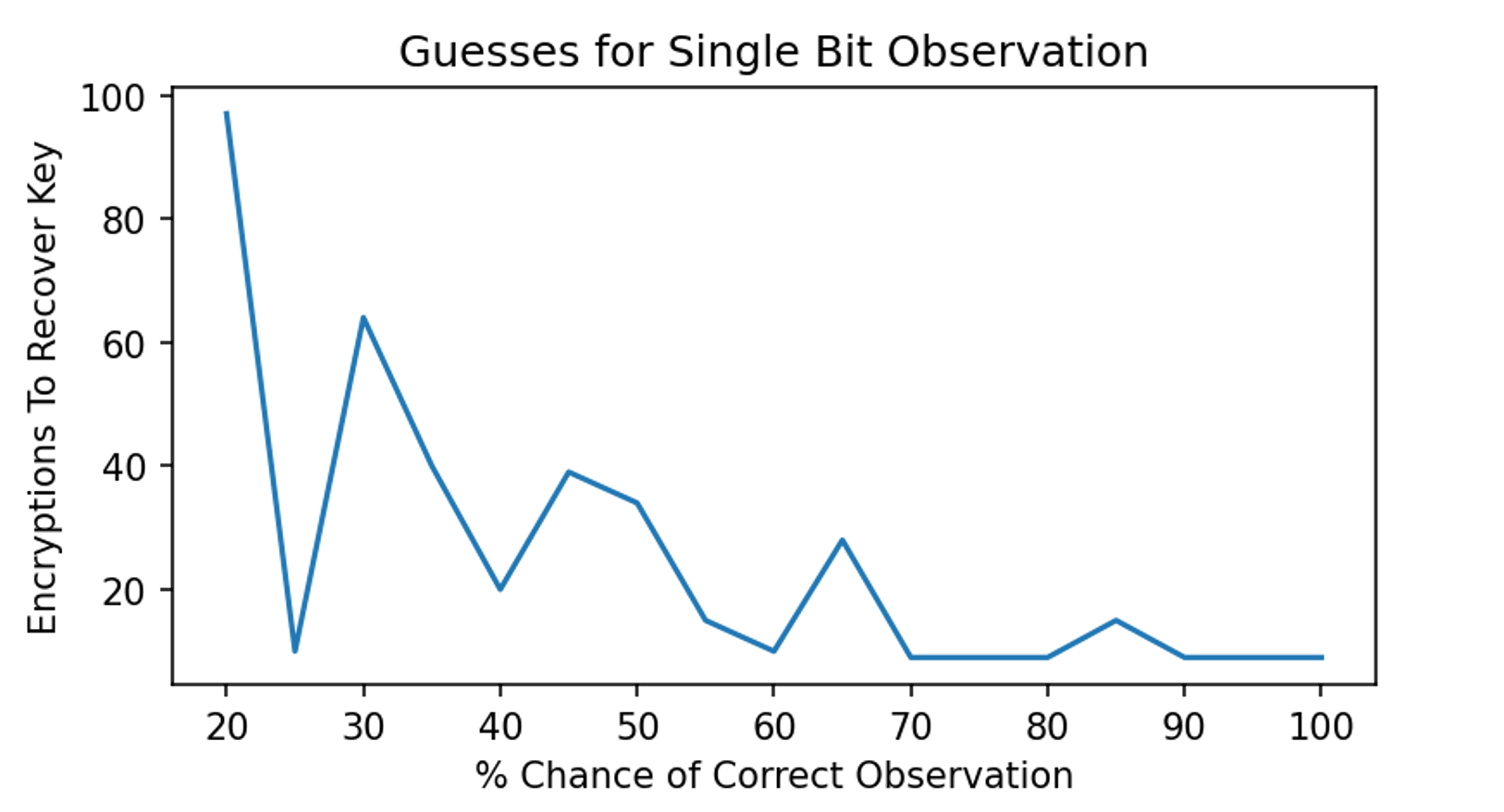
1 | Found key at 20 % correct data with 97 encryptions |
对结果画图
1 | import matplotlib.pylab as plt |
从图可知,70%以上正确率的基本上都只需要少量数据就可以恢复正确的key
Reference
 wechat
wechat alipay
alipay